
Oban's Pro package provides plugins, extensions and workers that build on top of the not-very-primitive-primitives provided by Oban. The components plug into your application to make complex job orchestration simple to reason about. In this post we're going to take a tour of the workers included in Pro and explore some real-world use-cases where each one shines. This is where workers stop being polite, and start getting real.
Batch Worker
The Batch worker was the original worker bundled with Pro. It allows applications to coordinate the execution of tens, hundreds or thousands of related jobs in parallel. Batch workers can define optional callbacks that execute as a separate job when any of these conditions are matched:
- all jobs in the batch are attempted at least once
- all jobs in the batch have completed successfully
- any jobs in the batch have exhausted retries or been manually cancelled
- all jobs in the batch have either a
completedordiscardedstate
The concept is simple enough. How about an example?
Batch Example
Batches are ideal for map/reduce style operations where you need to parallelize many jobs across separate nodes and then aggregate the result.
Imagine you have a service that thumbnails images and then archives them on demand. While you could do all of the thumbnailing and archiving in a single job, it wouldn't scale horizontally across nodes and it'd lose all progress when the node restarts. Instead, you can model processing as a batch where each job thumbnails a single image and a callback generates the final archive.
We'll define a batch thumbnailer with callbacks for when the entire batch is completed or retries are exhausted:
defmodule MyApp.Workers.BatchThumbnailer do
use Oban.Pro.Workers.Batch, queue: :media
alias MyApp.{Account, Media}
@impl true
def process(%Job{args: %{"uuid" => uuid, "url" => url}}) do
with {:ok, path} <- Media.download_original(url),
{:ok, path} <- Media.generate_thumbnail(path) do
Media.upload_thumbnail(uuid, path)
end
end
@impl Batch
def handle_completed(%Job{args: %{"batch_id" => "batch-" <> account_id}}) do
paths = Account.all_thumbnails(account_id)
with {:ok, file_name} <- Media.create_archive(paths) do
Media.upload_archive(account_id, file_name)
end
end
@impl Batch
def handle_exhausted(%Job{args: %{"batch_id" => "batch-" <> account_id}}) do
with {:ok, account} <- Account.fetch(account_id) do
Mailer.notify_archive_failure(account.email)
end
end
end
The process/1 function handles the mundane task of generating thumbnails for
each image. The handle_completed/1 and handle_exhausted/1 callbacks are
where the magic happens after all the thumbnailing is executed, as shown in this
flow diagram:
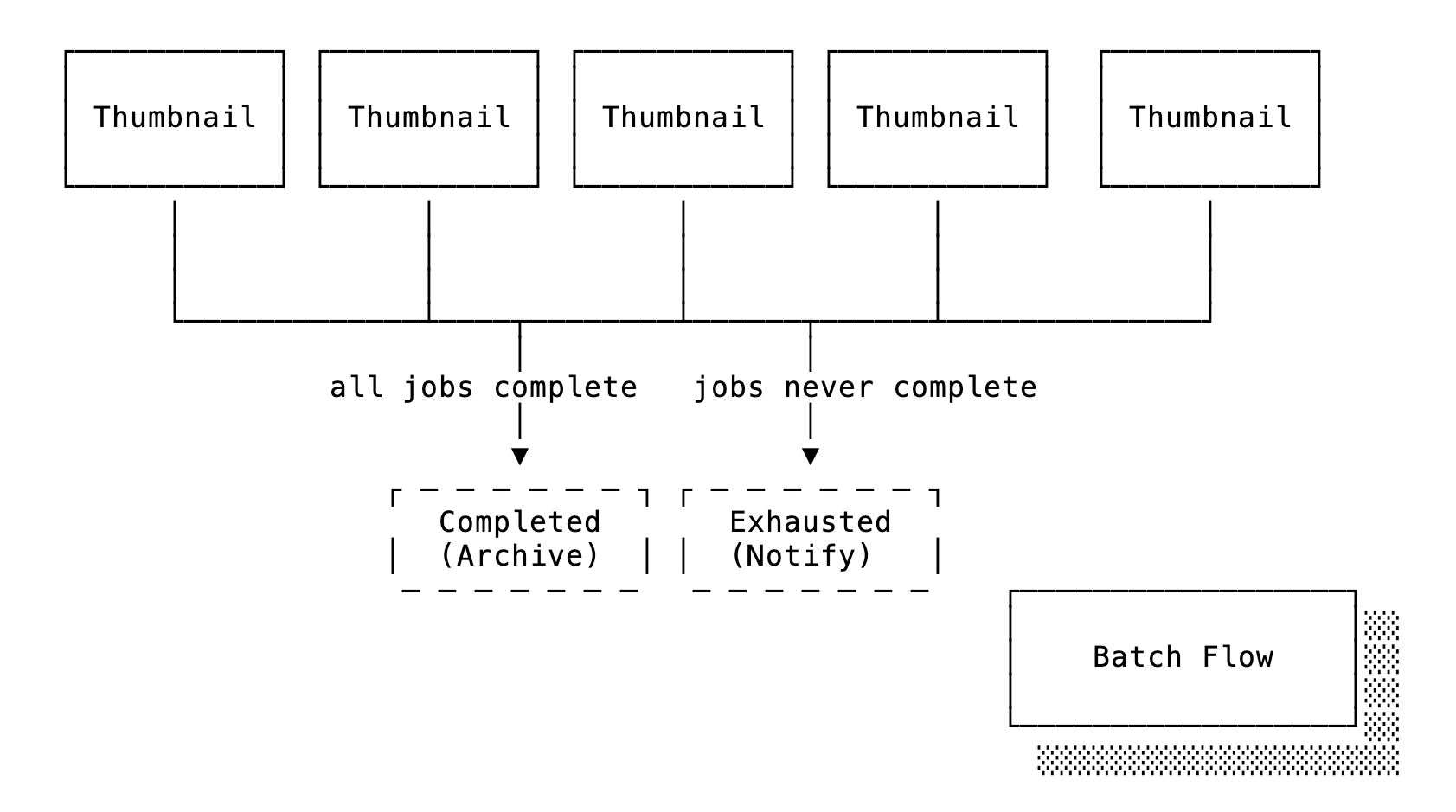
A batch is created through new_batch/1,2, which takes a list of args and
outputs a matching list of changesets ready for insertion. Typically the
batch_id is an auto-generated UUID, but here we're providing a value that
bakes in the account_id to simplify our callbacks.
alias MyApp.Account
alias MyApp.Workers.BatchThumbnailer
account_id
|> Account.all_images()
|> Enum.map(&Map.take(&1, [:uuid, :url]))
|> BatchThumbnailer.new_batch(batch_id: "batch-#{account_id}")
|> Oban.insert_all()
The thumbnailer we've built only defines a couple of the available callbacks. Other callbacks give more nuanced control over post-processing and batch management. Take a look at the Batch Guide to explore the other callbacks and see how to insert very large batches.
Chunk Worker

Chunks are the most recent worker addition, and by far our favorite worker name. A chunk worker executes jobs together in groups based on a size or a timeout option, e.g. when 1000 jobs are available or after 10 minutes have ellapsed. Multiple chunks can run in parallel within a single queue, and each chunk may be composed of many thousands of jobs. Combined, that makes for a massive increase in job throughput.
Aside from a massive increase in the possible throughput of a single queue, chunks are ideal as the initial stage of data-ingestion and data-processing pipelines.
Chunk Example
A chunk is unique among Oban workers because it receives a list of jobs which it operates on at the same time. That enables operations that span large amounts of data based on a naturally spaced stream of events. Sounds like a great fit for real-time ETL (extract, transform, and load) data-pipelines!
Pretend that our business handles thousands of disparate operations every minute, and we want to pass that data through our ETL pipeline as it flows in. A key part of our transformation is deduplicating and aggregating—something we need to perform in batches (not those batches).
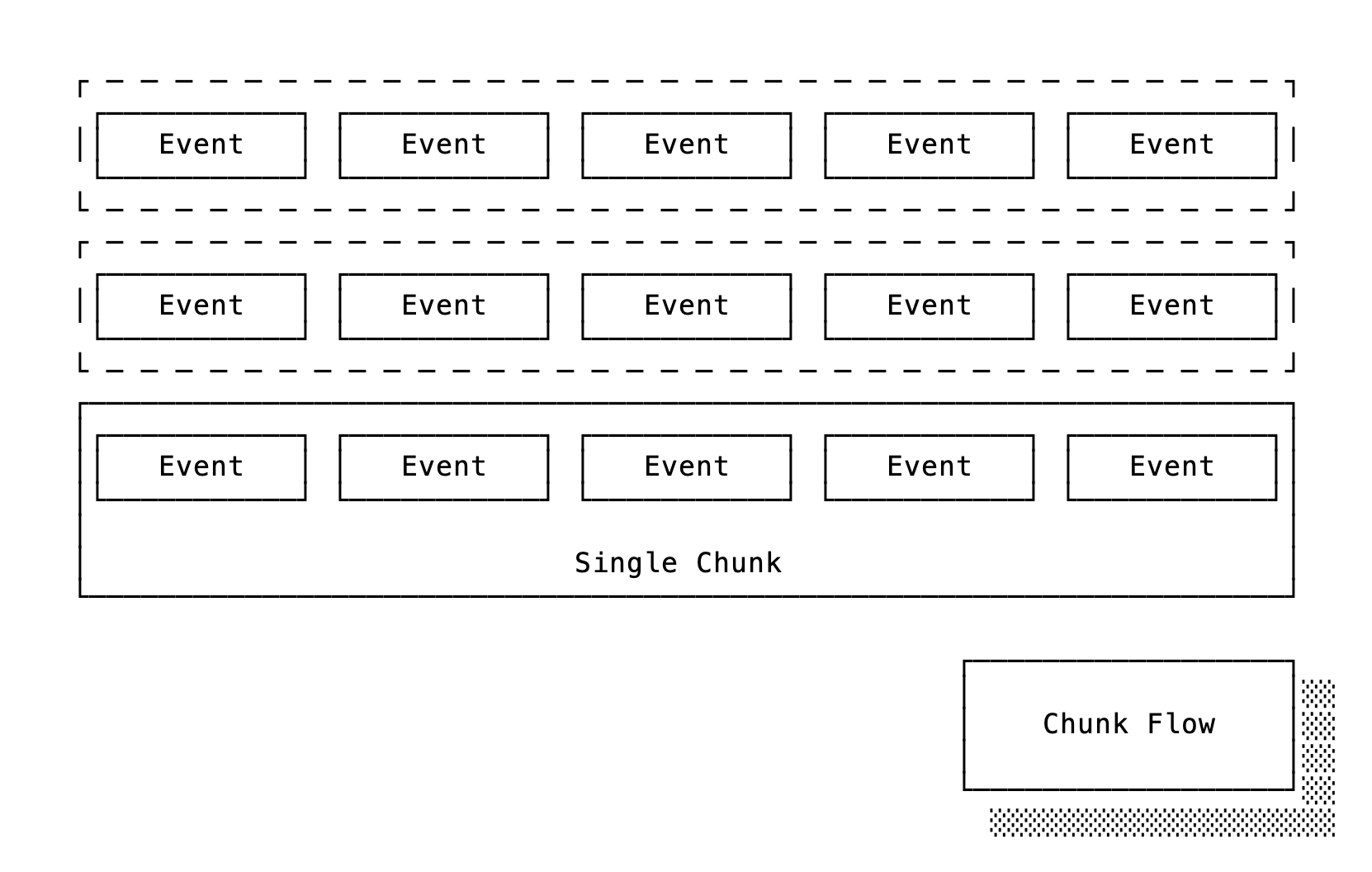
We'll define a worker that waits for a chunk of 10,000 available jobs or 10 minutes, whichever is first:
defmodule MyApp.Workers.Transformer do
use Oban.Pro.Workers.Chunk, size: 10_000, timeout: :timer.minutes(10)
alias MyApp.{Events, Warehouse}
@impl Chunk
def process(jobs) do
aggregated =
jobs
|> Stream.map(& &1.args)
|> Stream.map(&Events.fetch_data/1)
|> Stream.dedup_by(&Events.duplicate?/1)
|> Stream.transform([], &Events.aggregate/2)
|> Enum.to_list()
with {:error, reason} <- Warehouse.insert(aggregated) do
{:error, reason, jobs}
end
end
end
Assuming our various Events functions handle the data fetching, duplicate
checking, and aggregation logic, this is all we need to process groups of
events. The chunk worker fetches jobs from the database in a single call, passes
them to process/1 as a list, and then tracks them based on the return value.
When inserting data into the Warehouse fails, all of the jobs are flagged as
having errored and can be retried again later. Likewise, if the node crashes or
somebody trips over the power cord we have a guarantee that the chunk will run
again.
The Chunk worker draws on aspects of GenStage, Flow, and Broadway, but because it is implemented in Oban it has the persistence and reliability of a database backed queue. See the Chunk Guide for more usage and error handling details.
Workflow Worker
Workflows are the most powerful worker abstraction provided with Pro, and they have the dubious honor of the most redundant "worker" name. They enable fast, reliable, and inspectable execution of related tasks. Within a workflow, jobs compose together based on explicit dependencies that control the flow of execution. Essentially, workflows are a directed acyclic graph of jobs.
Where a batch or chunk needs homogeneous worker modules (all the same type of job), a workflow can span any combination of worker modules. Dependencies between the jobs are evaluated before the jobs are inserted into the database and then Oban does the rest, enforcing ordered execution even across multiple nodes.
Workflow Example
Workflows are ideal when there are dependencies between jobs, where downstream jobs rely on the success or side-effects of their upstream dependencies.
For this example we'll look at a video ingestion pipeline. As users upload videos we want to process and analyze them before sending a notification that processing is finished. Processing involves a number of jobs that are CPU intensive, call to functions outside the BEAM, or make network calls—all things that are slow and error prone. It would be a shame if we made it through most of the work only to fail on the last step! Instead, let's split the steps up into distinct jobs that we can scale and retry independently.
Overall we have the following workers that we'll pretend all exist and work in
isolation: Transcode, Transcribe, Indexing, Recognize, Sentiment,
Topics and Notify. Some jobs must run sequentially while others may run in
parallel. The execution graph should look like this:
Translating that into code, here's what the Transcode.process_video/1 function
would look like:
defmodule MyApp.Workers.Transcode do
use Oban.Pro.Workers.Workflow
alias MyApp.Workers.{Transcribe, Indexing, Recognize}
alias MyApp.Workers.{Sentiment, Topics, Notify}
def process_video(video_id) do
args = %{id: video_id}
new_workflow()
|> add(:transcode, new(args))
|> add(:transcribe, Transcribe.new(args), deps: [:transcode])
|> add(:indexing, Indexing.new(args), deps: [:transcode])
|> add(:recognize, Recognize.new(args), deps: [:transcode])
|> add(:sentiment, Sentiment.new(args), deps: [:transcribe])
|> add(:topics, Topics.new(args), deps: [:transcribe])
|> add(:notify, Notify.new(args), deps: [:indexing, :recognize, :sentiment])
|> Oban.insert_all()
end
# ...
end
Notice that we start a workflow and then declare jobs with a name and an optional set of dependencies. No, you aren't imagining things, it does look a lot like an Ecto.Multi.
We kick it all off by passing a video_id, which we'll pretend is the id of a
persisted video record with a URL and a handful of other attributes we need for
processing:
{:ok, _jobs} = MyApp.Workers.Transcode.process_video(video_id)
Once everything is inserted we're guaranteed that the transcode job runs
first, and only after it succeeds will transcript, indexing and recognize
work, and so on. All of a workflow's coordination happens behind the scenes and
you can focus on making the workers do what your business needs them to.
For more details, options, and the full API see the Workflow Guide.
Making Difficult Workflows Simple
We've covered a lot of concepts in the worker examples! To recap, our cast of composable workers are:
- Batch — Track execution of related jobs and run callbacks based on group state
- Chunk — Accumulate jobs by size or time and process them all at once from a single function
- Workflow — Define dependencies between jobs and execute them in a strict order
Our goal is to make complex job interaction simple for you by offloading all the complexity to Pro. Hopefully, you've identified some solutions that are helpful to you, your clients or your business.
Pro has much more to offer, which we'll explore it in future posts. In the meantime, check out the full list of features or peruse the guides to learn more.
As usual, if you have any questions or comments, ask in the Elixir Forum. For future announcements and insight into what we're working on next, subscribe to our newsletter.