Oban Articles
-

Bridging Elixir and Python with Oban
Using Oban to seamlessly exchange durable jobs between Elixir and Python applications through a shared PostgreSQL database.
-

Oban Comes to Python
Introducing fully operational, PostgreSQL-backed, fully async implementations of Oban and Oban Pro for Python.
-

Unlocking Agentic Workflows with Oban Pro
Reliable agentic workflows in Oban Pro: cascading jobs, human-in-the-loop checkpoints, dynamic grafting, and transactional guarantees.
-

Weaving Stories with Cascading Workflows
Using cascading workflows with context sharing pipelines to generate a collection of illustrated children's stories.
-

Oban Pro v1.6 Released
The Pro v1.6 release candidate adds sub-workflows, overhauled partitioning, global burst mode, and much more.
-

OSS Oban Web and Oban v2.19
From open sourcing Oban Web, to releasing Oban with MySQL support, Web v2.11, and plan simplifications
-

Oban Pro v1.5 Launch Week—Day 5
The last day of Oban Pro v1.5 launch week, putting it all together with hybrid compositions and announcing the release candidate.
-

Oban Pro v1.5 Launch Week—Day 4
The fourth day of Oban Pro v1.5 launch week, covering overhauled batches and improved workflows.
-

Oban Pro v1.5 Launch Week—Day 3
The third day of Oban Pro v1.5 launch week, dedicated to the @job function decorator which converts any function into a background job.
-

Oban Pro v1.5 Launch Week—Day 2
The second day of Pro v1.5 launch week, covering enhanced uniqueness and distributed PostgreSQL.
-

Oban Pro v1.5 Launch Week—Day 1
The first day of Oban Pro v1.5 launch week, covering unified migrations, worker aliases, and radically improved chaining.
-

The Oban Pros—Our Story on the Changelog Podcast
We joined The Changelog to discuss the legacy of Oban Pro, Elixir as a mature niche, and the beauty of mom-and-pop lifestyle businesses.
-

Enhancing Oban Job Error Reporting
Tips and techniques to make Oban job errors easier to identify, differentiate, and diagnose in monitoring systems like Sentry
-

Optimizing Connections and Bloat with Oban Pro
Survey the recent additions to Oban Pro that drastically reduce transactions, pool contention, database bloat, and overall system load for high throughput systems
-
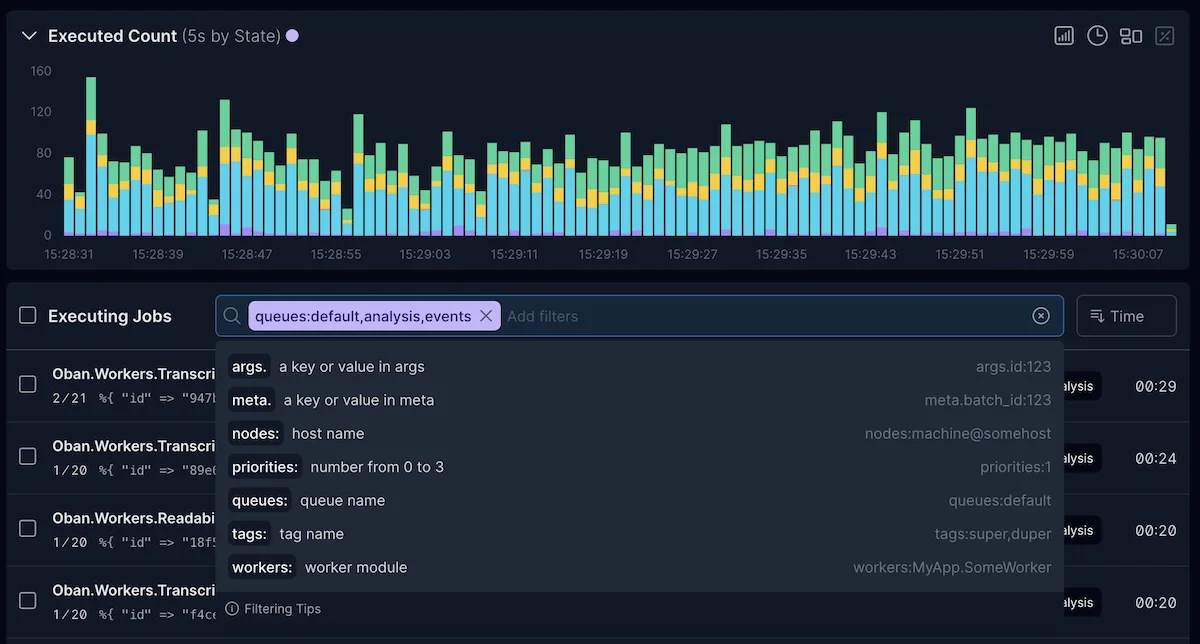
Oban Web v2.10 Released
Details and demos of the features in Oban Web v2.10, including realtime charts, filtering with auto-complete, and distributed metrics.
-

Oban Pro v0.14 Released
Details about the features in Oban Pro's v0.14 release including horizontal auto-scaling, a schema for structured args, partitioning chunks, and faster batching.
-

Oban Starts Where Tasks End
Why Elixir's Task module isn't enough for critical background work, and how Oban provides the persistence, retries, scheduling, and distribution you need.
-

One Million Jobs a Minute with Oban
Explore Oban's performance boundaries and system load through a journey to processing millions of jobs a minute.
-

Oban v2.11, Pro v0.10, and Web v2.9 Released
Oban v2.11 introduces centralized leadership and a PG notifier for reduced resource usage, plus new features in Pro v0.10 and Web v2.9.
-

Using Oban to License Oban
A behind-the-scenes look at how we use Oban to run the live dashboard demo, process payments, manage licenses, and handle webhooks reliably.
-

Composing Jobs with Oban Pro
A breakdown of Oban Pro's specialized workers including Batch for parallel execution, Chunk for grouped processing, and Workflow for multi-step job pipelines.
-

Self Hosting Oban Packages
How we built a self-hosted hex repo for Oban Web and Oban Pro using hex_core and a global CDN, with instructions for updating your config.