
The recently announced Pro v1.6 RC introduced a treasure trove of new workflow features. That calls for a demonstration of the new silky smooth approach to building workflows.
Said pageant doesn't require any domain knowledge or business logic; just some whimsy and a really loose understanding of graphs. On to the Fire Saga!
Say What About a Fire Saga?
It's called "Fire Saga" (🔥📖), because we like Eurovision and thought it sounded catchy. A saga is an epic story, they're both nouns...it's awesome. Don't get too wrapped up in the name.
Anyhow, FireSaga is a workflow that generates a collection of children's stories based on a topic
using generative AI. The authors are selected at random, then a short children's story and an
illustration are generated for each author before it's all packaged together with cover art in a
tidy markdown file.
It's all coordinated using an Oban Workflow.
Why Oban Workflows?
Performing a set of coordinated tasks with dependencies between them is precisely what workflows are meant to do. Think of workflows as a pipe operator for directed, distributed, persistent map-reduce.
Let's break that buzzword soup down:
-
Directed-jobs progress in a fixed order, whether running linearly, fanning out, fanning in, or running in parallel.
-
Distributed-jobs run seamlessly on all available nodes transparently, without extra coordination from your application.
-
Persistent-processes crash, applications restart, and a workflow must be able to pick up where it left off.
A few more essential traits for good measure:
-
Retryable-LLMs are notoriously unreliable, whether from timeouts, rate limiting, or unexpected nonsense responses. Retries are crucial to having reliable output.
-
Introspection-you need to track progress to see how a workflow is progressing, check timing information, and see errors wreaking havoc on the pipeline.
See? Some say, workflows are a perfect fit for a multi-stage, interdependent, story generating pipeline making unreliable API calls. Well, we say so.
Building the Workflow
It would be possible to build FireSaga using standard jobs in older style workflows. In that
case, each job would be in a separate module, and you would use Workflow functions to manually
fetch recorded output from upstream dependencies and weave it all together.
That'd be fine...but Pro v1.6 introduced context sharing, cascade mode, and sub workflows, which automates all of that.
To make a long saga short, "cascade mode" streamlines defining a workflow by passing accumulated context to each step. A context map, as well as output from each dependency, are passed to every function.
Kick it off with a workflow building function named build/1:
def build(opts) when is_list(opts) do
topic = Keyword.fetch!(opts, :topic)
count = Keyword.fetch!(opts, :chapters)
range = 0..(count - 1)
Workflow.new()
|> Workflow.put_context(%{count: count, topic: topic})
|> Workflow.add_cascade(:authors, &gen_authors/1)
|> Workflow.add_cascade(:stories, {range, &gen_story/2}, deps: :authors)
|> Workflow.add_cascade(:images, {range, &gen_image/2}, deps: ~w(authors stories))
|> Workflow.add_cascade(:title, &gen_title/1, deps: :stories)
|> Workflow.add_cascade(:cover, &gen_cover/1, deps: :stories)
|> Workflow.add_cascade(:print, &print/1, deps: ~w(authors cover images stories title))
end
There's a lot going on in there:
-
We stash a context map containing the number of chapters and chosen topic with
put_context/2to share data with all workflow steps. -
We're using
add_cascade/4to create steps that receive both the context map and the output from their dependencies. -
The function captures (e.g.,
&gen_authors/1) define the actual work performed at each step. That way, the compiler can verify functions exist andadd_cascade/4verifies they have the correct arity. -
For the
:storiesand:imagessteps, we use the{enum, capture}variant ofadd_cascade/4to create sub-workflows that fan out across our range of chapters. -
Dependencies are clearly specified with the
depsoption, ensuring steps only run after their prerequisites complete, (including deps on an entire sub-workflow). -
The final
:printstep has dependencies on all previous steps, ensuring it only runs once everything else is complete.
It's easier to understand the flow of data with some visualization. Time for to_mermaid/1:
[chapters: 3, topic: "hamsters and gooey kablooies"]
|> FireSaga.build()
|> Oban.Pro.Workflow.to_mermaid()
Passing the output through to mermaid outputs a spiffy, helpful diagram:
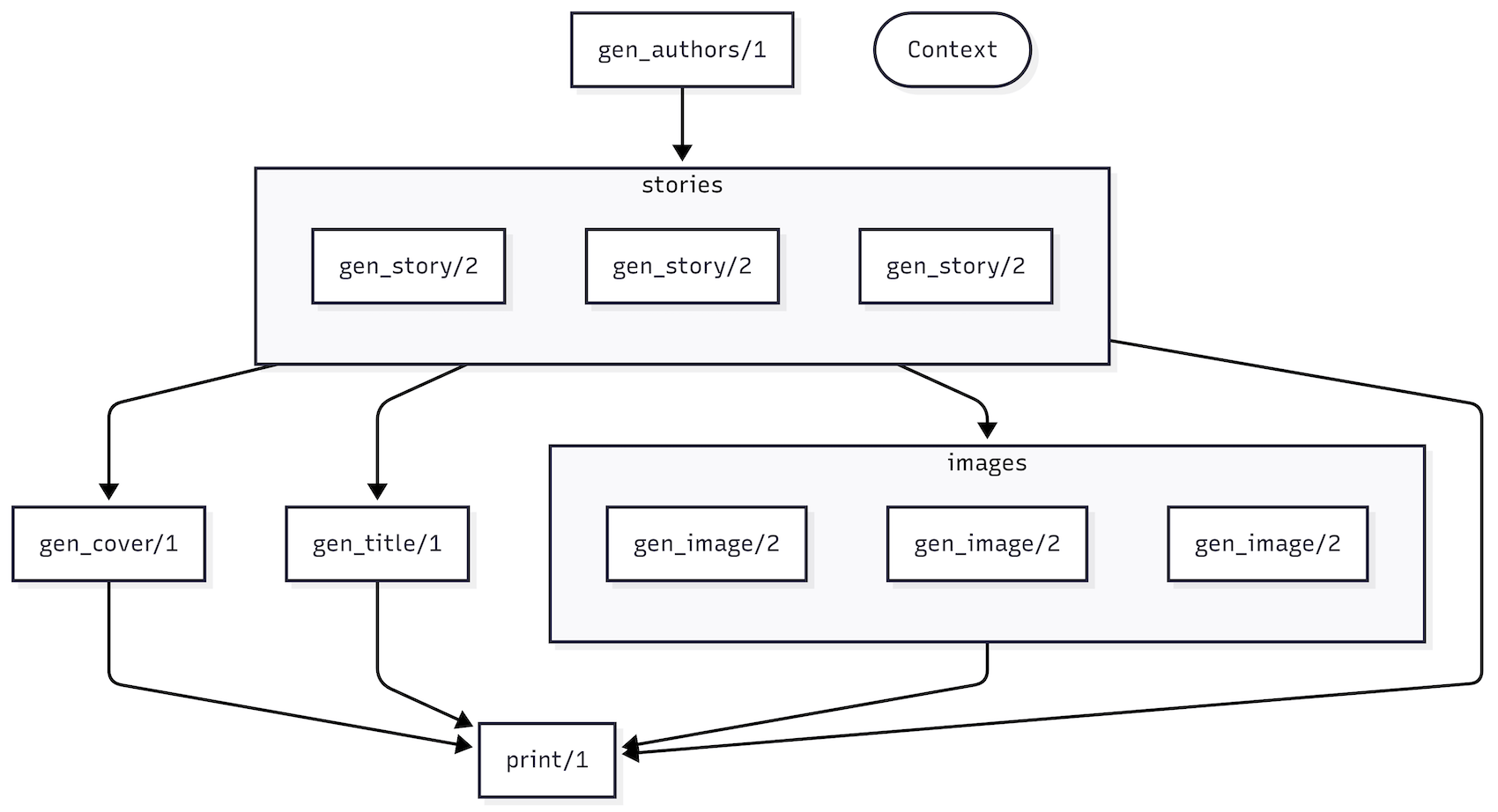
That's all for the workflow. On to the actual functions.
Cascade Functions
Cascade functions are surprisingly simple—they're just regular functions that accept a context map as their single argument. You can define them in any module without special annotations or boilerplate.
Let's check out the gen_authors/1 implementation:
def gen_authors(%{count: count}) do
prompt = """
Generate an unordered list of thirty prominent children's authors.
Use a leading hyphen rather than numbers for each list item.
"""
prompt
|> LLM.chat!()
|> String.split("\n", trim: true)
|> Enum.map(&String.trim_leading(&1, "- "))
|> Enum.take_random(count)
end
It's using a simple LLM module to call a chat endpoint (you can check it out on GitHub). The
output is a list of authors (Beverly Cleary, Shel Silverstein, etc.), which is recorded and made
available in the downstream functions.
Next downstream is gen_story/2, which runs as part of a sub-workflow and receives slightly
different arguments. The first argument is an element from the enumerable (in this case, the
index), followed by the accumulated context:
def gen_story(index, %{authors: authors, topic: topic}) do
author = Enum.at(authors, index)
LLM.chat!("""
You are #{author}. Write a one paragraph story about "#{topic}" including a title.
""")
end
The gen_image/2 function is another sub-workflow step that receives two arguments. Since the
images step depends on both authors and stories, it has access to their outputs in the
context map. This allows it to generate an illustration specifically tailored to each author's
story (um, usually, it stinks at Shel Silverstein):
def gen_image(index, %{authors: authors, stories: stories}) do
author = Enum.at(authors, index)
story = Map.get(stories, to_string(index))
LLM.image!("""
You are #{author}. Create an illustration for the children's story: #{story}
""")
end
Both gen_title/1 and gen_cover/1 follow a similar structure, using output from dependencies
and making LLM calls, so we'll omit them here. Finally, the print/1 function pulls it all
together:
def print(context) do
context.images
|> Enum.map(fn {idx, url} -> {url, "image_#{idx}.png"} end)
|> Enum.concat([{context.cover, "cover.png"}])
|> Enum.each(fn {url, path} -> Req.get!(url, into: File.stream!(path)) end)
@template
|> EEx.eval_string(Keyword.new(context))
|> then(&File.write!("story.md", &1))
end
We love it when a plan comes together.
What About the Output?
How entertaining is a story-generating pipeline without some sample output? (Very little, unless you really like mermaid diagrams. You know who you are 😉)
Here's a sample chapter that FireSaga generated about the topic "bento box lunches" in the style
of Dav Pilkey:
Bento Box Adventures: Lunchables in Imagination!

Inspired By: Dav Pilkey
In a school where lunchboxes were portals to adventure, Benny the brave bento box dreamed of a day when he would be filled with extraordinary foods. One sunny morning, he woke up to find his lid popped open, revealing a colorful array of sushi-shaped gummy candies, rainbow rice, and tiny veggie heroes ready to save lunchtime! As Benny rolled into the cafeteria, he teamed up with Tina the trendy thermos and Sammy the snack-sized container...
Captivating stuff. Gummy candies and veggie heroes you say!?
Workflows in Action
So, that's cascading workflows. They eliminate all the boilerplate of multiple workers and collocate an entire pipeline of functions into a single module. It's a much more convenient - dare we say, "elegant" - way to build workflows.
If you'd like to experiment with FireSaga yourself, check out the repository.
(You'll need two things to get started—an Oban Pro license and some OpenAI keys).
As usual, if you have any questions or comments, ask in the Elixir Forum. For future announcements and insight into what we're working on next, subscribe to our newsletter.